
Top 10 Deep Learning Algorithms You Should Know in 2024
Deep learning has gained massive popularity in scientific computing, and its algorithms are widely used by industries that solve complex problems. All deep learning algorithms use different types of neural networks to perform specific tasks.
This tutorial examines essential artificial neural networks and how deep learning algorithms work to mimic the human brain.
What Is Deep Learning?
Deep learning uses artificial neural networks to perform sophisticated computations on large amounts of data. It is a type of machine learning that works based on the structure and function of the human brain.
Deep learning algorithms train machines by learning from examples. Industries such as health care, eCommerce, entertainment, and advertising commonly use deep learning.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
Defining Neural Networks
A neural network is structured like the human brain and consists of artificial neurons, also known as nodes. These nodes are stacked next to each other in three layers:
- The input layer
- The hidden layer(s)
- The output layer
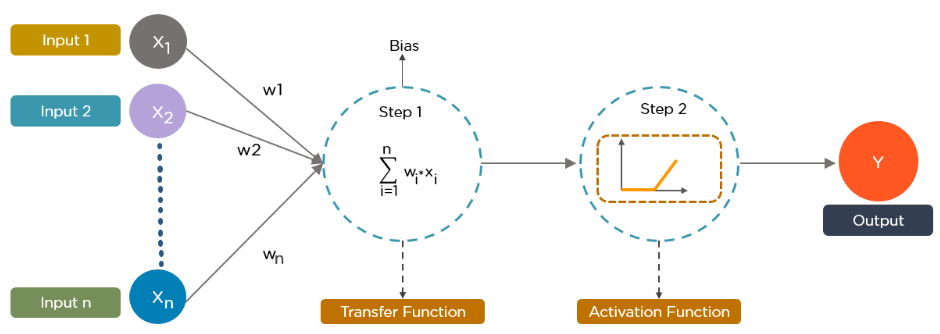
Data provides each node with information in the form of inputs. The node multiplies the inputs with random weights, calculates them, and adds a bias. Finally, nonlinear functions, also known as activation functions, are applied to determine which neuron to fire.
PGP in Caltech AI & Machine Learning
Advance Your AI & ML Career With a PGPEnroll Now
How Deep Learning Algorithms Work?
While deep learning algorithms feature self-learning representations, they depend upon ANNs that mirror the way the brain computes information. During the training process, algorithms use unknown elements in the input distribution to extract features, group objects, and discover useful data patterns. Much like training machines for self-learning, this occurs at multiple levels, using the algorithms to build the models.
Deep learning models make use of several algorithms. While no one network is considered perfect, some algorithms are better suited to perform specific tasks. To choose the right ones, it’s good to gain a solid understanding of all primary algorithms.
A Cyber security BootCamp serves as a gateway for individuals to delve into the intricate world of deep learning algorithms within the context of cybersecurity. Participants in this program gain insights into how deep learning techniques can be employed to enhance threat detection, anomaly recognition, and predictive analysis.
Top 10 Deep Learning Algorithms
1. Convolutional Neural Networks (CNNs)
CNNs are a deep learning algorithm that processes structured grid data like images. They have succeeded in image classification, object detection, and face recognition tasks.
How it Works
- Convolutional Layer: This layer applies a set of filters (kernels) to the input image, where each filter slides (convolves) across the image to produce a feature map. This helps detect various features such as edges, textures, and patterns.
- Pooling Layer: This layer reduces the dimensionality of the feature maps while retaining the most essential information. Common types include max pooling and average pooling.
- Fully Connected Layer: After several convolutional and pooling layers, the output is flattened and fed into one or more fully connected (dense) layers, culminating in the output layer that makes the final classification or prediction.
2. Recurrent Neural Networks (RNNs)
RNNs are designed to recognize patterns in data sequences, such as time series or natural language. They maintain a hidden state that captures information about previous inputs.
How it Works
- Hidden State: At each time step, the hidden state is updated based on the current input and the previous hidden state. This allows the network to maintain a memory of past inputs.
- Output: The hidden state generates an output at each time step. The network is trained using backpropagation through time (BPTT) to minimize prediction error.
3. Long Short-Term Memory Networks (LSTMs)
LSTMs are a special kind of RNN capable of learning long-term dependencies. They are designed to avoid the long-term dependency problem, making them more effective for tasks like speech recognition and time series prediction.
How it Works
- Cell State: LSTMs have a cell state that runs through the entire sequence and can carry information across many steps.
- Gates: Three gates (input, forget, and output) control the flow of information:
- Input Gate: Determines which information from the current input should be updated in the cell state.
- Forget Gate: Decides what information should be discarded from the cell state.
- Output Gate: Controls the information that should be outputted based on the cell state.
4. Generative Adversarial Networks (GANs)
GANs generate realistic data by training two neural networks in a competitive setting. They have been used to create realistic images, videos, and audio.
How it Works
- Generator Network: Creates fake data from random noise.
- Discriminator Network: Evaluates the authenticity of the data, distinguishing between real and fake data.
- Training Process: The generator and discriminator are trained simultaneously. The generator tries to fool the discriminator by producing better fake data, while the discriminator tries to get better at detecting counterfeit data. This adversarial process leads to the generator producing increasingly realistic data.
Master Tools You Need For Becoming an AI Engineer
AI Engineer Master’s ProgramExplore Program
5. Transformer Networks
Transformers are the backbone of many modern NLP models. They process input data using self-attention, allowing for parallelization and improved handling of long-range dependencies.
How it Works
- Self-Attention Mechanism: This mechanism computes the importance of each part of the input relative to every other part, enabling the model to weigh the significance of different words in a sentence differently.
- Positional Encoding: Adds information about the position of words in the sequence since self-attention doesn’t inherently capture sequence order.
- Encoder-Decoder Architecture: Consists of an encoder that processes the input sequence and a decoder that generates the output sequence. Each consists of multiple layers of self-attention and feed-forward networks.
6. Autoencoders
Autoencoders are unsupervised learning models for tasks like data compression, denoising, and feature learning. They learn to encode data into a lower-dimensional representation and then decode it back to the original data.
How it Works
- Encoder: Maps the input data to a lower-dimensional latent space representation.
- Latent Space: Represents the compressed version of the input data.
- Decoder: Reconstructs the input data from the latent representation.
- Training: The network minimizes the difference between the input and the reconstructed output.
7. Deep Belief Networks (DBNs)
DBNs are generative models composed of multiple layers of stochastic, latent variables. They are used for feature extraction and dimensionality reduction.
How it Works
- Layer-by-Layer Training: DBNs are trained in a greedy, layer-by-layer fashion. Each layer is trained as a Restricted Boltzmann Machine (RBM), which learns to reconstruct its input.
- Fine-Tuning: After pretraining the layers, the entire network can be fine-tuned using backpropagation for specific tasks.
8. Deep Q-Networks (DQNs)
DQNs combine deep learning with Q-learning, a reinforcement learning algorithm, to handle environments with high-dimensional state spaces. They have been successfully applied to tasks such as playing video games and controlling robots.
How it Works
- Q-Learning: Uses a Q-table to represent the value of taking an action in a given state.
- Deep Neural Network: Replaces the Q-table with a neural network that approximates the Q-values for different actions given a state.
- Experience Replay: Stores past experiences in a replay buffer and samples from it to break the correlation between consecutive experiences, improving training stability.
- Target Network: A separate network with delayed updates to stabilize training.
9. Variational Autoencoders (VAEs)
VAEs are generative models that use variational inference to generate new data points similar to the training data. They are used for generative tasks and anomaly detection.
How it Works
- Encoder: Maps input data to a probability distribution in the latent space.
- Latent Space Sampling: Samples from the latent space distribution to introduce variability in the generated data.
- Decoder: Generates data from the sampled latent representation.
- Training: This method combines reconstruction loss and a regularization term to encourage the latent space to follow a standard normal distribution.
10. Graph Neural Networks (GNNs)
GNNs generalize neural networks to graph-structured data. They are used for social network analysis, molecular structure analysis, and recommendation systems.
How it Works
- Graph Representation: Nodes represent entities, and edges represent relationships between entities.
- Message Passing: Nodes aggregate information from their neighbors to update their representations. This process can be repeated for several iterations.
- Readout Function: After message passing, a readout function aggregates node representations to produce a graph-level representation for tasks like classification or regression.
Your AI/ML Career is Just Around The Corner!
AI Engineer Master’s ProgramExplore Program
Conclusion
As we navigate through 2024, the landscape of deep learning continues to evolve, bringing forth innovative algorithms that push the boundaries of what machines can achieve. From the image recognition prowess of Convolutional Neural Networks (CNNs) to the transformative capabilities of Transformer Networks, these top 10 deep learning algorithms are at the forefront of technological advancement. Whether you’re delving into natural language processing, generative models, or reinforcement learning, these algorithms offer powerful tools to solve complex problems across various domains.
Continuous learning and skill enhancement are crucial to stay ahead in this rapidly advancing field. One excellent opportunity to deepen your understanding and expertise is the Caltech Post Graduate Program in AI and Machine Learning. This comprehensive course provides in-depth knowledge and hands-on experience with the latest AI and machine learning technologies, guided by experts from one of the world’s leading institutions.
FAQs
Q1. Which Algorithm is Best in Deep Learning?
Multilayer Perceptrons (MLPs) are the best deep learning algorithm. It is one of the oldest deep learning techniques used by several social media sites, including Instagram and Meta. This helps to load the images in weak networks, assists in data compression, and is often used in speed and image recognition applications.
Q2. Which is an Example of a Deep Learning Algorithm?
A few of the many deep learning algorithms include Radial Function Networks, Multilayer Perceptrons, Self Organizing Maps, Convolutional Neural Networks, and many more. These algorithms include architectures inspired by the human brain neurons’ functions.
Q3. Is CNN a Deep Learning Algorithm?
Yes, CNN is a deep learning algorithm responsible for processing animal visual cortex-inspired images in the form of grid patterns. These are designed to automatically detect and segment-specific objects and learn spatial hierarchies of features from low to high-level patterns.
Q4. What are the 3 Layers of Deep Learning?
The three-layered neural network consists of three layers – input, hidden, and output layer. When the input data is applied to the input layer, output data in the output layer is obtained. The hidden layer is responsible for performing all the calculations and ‘hidden’ tasks.
Q5. How does a Deep Learning Model Work?
Deep learning models are trained using a neural network architecture or a set of labeled data that contains multiple layers. They sometimes exceed human-level performance. These architectures learn features directly from the data without hindrance to manual feature extraction.
Q6. Which are the Best Deep Learning Algorithms?
Whether you are a beginner or a professional, these top three deep learning algorithms will help you solve complicated issues related to deep learning: CNNs or Convolutional Neural Networks, LSTMs or Long Short Term Memory Networks and RNNs or Recurrent Neural Networks (RNNs).
link







