
Leveraging machine learning techniques for image classification and revealing social media insights into human engagement with urban wild spaces

This research aims to explore human engagement with urban wild spaces by leveraging the vast amount of human-generated data available on social media platforms such as Instagram, Flickr and Facebook. The proposed approach in this research is to analyse publicly available posts on social media platforms that include images, image captions, hashtags, and human interactions such as comments. This study seeks to uncover such posts to see how people interact with and perceive these urban wild spaces. This research project begins by scraping and gathering data from social media using a hashtag-based approach, specifically targeting posts related to urban wild spaces. After collecting this raw data, machine learning techniques are applied to analyse and clean it, transforming it into a structured dataset that accurately reflects information about these urban natural areas. The process involves training machine learning models with supervised labelled image data related to urban wild spaces, enabling them to learn and recognise relevant features. These models are then tested on the scraped social media data, enhancing the data’s clarity and relevance.
The design of the proposed method is driven by the need to bridge the gap between indirect measurements of public engagement, such as remote sensing or static survey data, and real-time, human-centric evidence. The approach captures authentic, spontaneous interactions with urban wild spaces at scale by focusing on image-based content shared on social media. The choice to use a hashtag-based scraping technique allows for domain-specific filtering and reflects how users self-categorise their experiences. The use of supervised learning models—specifically Convolutional Neural Networks (CNNs), DBSCAN, and Autoencoders—was informed by their effectiveness in image classification, noise filtering, and clustering, which are crucial for dealing with unstructured and noisy social media data. The complexity of the proposed solution lies in its multi-stage pipeline: it involves raw data extraction, extensive preprocessing to ensure data quality, feature extraction through deep learning, and iterative model training and evaluation. This layered architecture balances computational efficiency and model robustness, enabling scalable analysis without compromising interpretability or performance. These design decisions collectively support the goal of producing a high-quality, machine-readable dataset that reflects genuine human engagement with urban wild environments. The following Fig. 1 proposed architecture shows each component of this research.
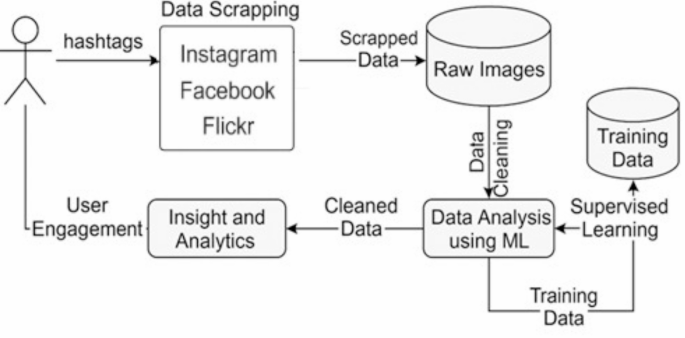
The pipeline of experimental procedure.
Detailed explanations of the model training, testing procedures, and the resulting data insights are presented in the data analysis and results section. The following steps outline the methodology in detail to provide a comprehensive understanding of the research approach.
Data scrapping
The first phase of this research involves systematically scraping data from social media platforms mentioned earlier, which are popular for sharing images and user-generated content.
This research leverages the Meta APIs (Facebook and Instagram are part of the same organisation, “Meta.” The Meta Developers API offers access to Meta’s platform data, allowing developers to integrate Facebook, Instagram, and WhatsApp functionalities into their applications. It also enables data scraping34such as extracting user-generated content, posts, and metadata while ensuring compliance with Meta’s policies. However, developers must follow strict guidelines to ensure data privacy and compliance with Meta’s terms of service), combined with hashtag-based techniques (Hashtags are presented in the Appendix of this paper) to scrape data specifically related to urban wild spaces. By collecting and analysing posts, images, and other user-generated content tagged with relevant hashtags, the study aims to explore public engagement, perceptions, and interactions with these natural environments in urban settings. Hashtags serve as critical identifiers for filtering content that reflects urban wild spaces. By focusing on urban wild spaces as a theme, the goal is to compile a diverse dataset that reflects public perception and usage of such spaces through visual and textual content. Furthermore, this research also considers Flickr API, which provides developers with access to Flickr’s vast database of images, allowing them to search, retrieve, and interact with photos and metadata hosted on the platform. It supports functionalities such as searching for photos by tags, locations, or user accounts, uploading and managing images, and retrieving information about user profiles and photo statistics. However, this research has a limited scope as it exclusively relies on a tag-based (hashtags) approach to retrieve images.
Furthermore, data scraping is conducted using a set of predefined hashtags that are manually gathered from social media platforms. These hashtags are carefully curated to focus on topics related to urban wild spaces. To enhance their accuracy and relevance, a reflexive workshop is organised involving expert researchers who specialise in the study of urban wild spaces. During this workshop, the hashtags are refined and expanded to ensure they cover a broad range of relevant themes and interactions. This refinement process ensures that the final selection of hashtags is both relevant and comprehensive for capturing meaningful data. The scraped data reflects both seasonal and non-seasonal patterns in public engagement, enabling a more detailed and nuanced analysis of how people interact with and perceive urban wild spaces across different times of the year. This approach provides insights into temporal variations in engagement and allows researchers to observe shifts in public interest and interaction with these spaces.
However, after conducting the data scraping experiment, a raw dataset of images and metadata was collected (The raw data collected through the data scraping process, including images and metadata related to urban wild spaces from social media platforms, is detailed in the appendix) from social media platforms. This dataset includes a wide range of user-generated content tagged with hashtags related to urban wild spaces. At this stage, the raw data contains unfiltered information, including potential noise, irrelevant posts, and AI-generated images, requiring further cleaning to ensure its relevance and authenticity for analysis. The following Table 1 provides a detailed count of the scraped data collected from social media platforms, highlighting the volume of images related to urban wild spaces.
The following Fig. 2 illustrates examples of data scraped from Instagram that have been tagged with hashtags relevant to urban wild spaces, such as #urbanwildspace and #wildlife. However, the content varies in relevance to this research. Image 1 is an AI-generated image that has been incorrectly tagged as #urbanwildspace, showcasing how synthetic content can appear in user-generated datasets. Image 2 is also tagged with #urbanwildspace, but the content is irrelevant to urban wild spaces, highlighting the noise that often accompanies social media data due to inaccurate or unrelated tagging. In contrast, Image 3 is a correctly tagged photo of an urban wild space, aligning well with the research’s focus and representing authentic public engagement with these areas. Finally, Image 4 is another irrelevant image, tagged as #wildlife, which, while related to nature, does not fit the specific context of urban wild spaces emphasised in this study. These examples underline the challenges in filtering and cleaning social media data, where a mixture of accurate, synthetic, and unrelated content is often tagged similarly, complicating the process of isolating relevant information for meaningful analysis.
Furthermore, the data is illustrated in the Appendix section through Figs. S1, S2, S3, S4, and S5. These examples further illustrate the diversity and inconsistency in user-generated content across different social media platforms. Like Instagram, posts on Facebook often include shared media, low-resolution images, or unrelated visuals that are inaccurately tagged with nature-related hashtags. Similarly, while Flickr generally offers higher-quality images, it still includes a mix of relevant and irrelevant content due to inconsistent tagging practices. The inclusion of these examples in the Appendix serves to emphasise the complexity of the data cleaning process and the necessity of the machine learning models applied in this study to effectively filter noise and retain authentic images representing urban wild space engagement.

Example of raw images from Instagram.
Data analysis and experimental procedures
This section presents a comprehensive overview of the data analysis workflow and experimental procedures used in this study to develop and evaluate machine learning models (DBSCAN, Convolutional Neural Networks (CNN), and Convolutional Autoencoders (CAE)) applied to image datasets scraped from social media platforms. Each social media platform contributes diverse visual content tagged with urban wild space-related hashtags. The goal of this analysis was to detect and filter irrelevant, noisy, or AI-generated content and retain only authentic human-captured images that provide meaningful insights into public engagement with urban wild spaces.
Training dataset preparation and preprocessing
The foundation of our methodology lies in a meticulously curated training dataset constructed with the guidance of environmental science and urban ecology experts. This dataset includes thousands of images representing authentic urban wild spaces and was manually annotated to distinguish relevant content from noise, AI-generated imagery, and advertisements. The annotation process involved expert consensus and rigorous quality control to ensure consistency across all image labels.
The labelled dataset was split into training (80%) and testing (20%) sets. A stratified sampling method was used to maintain label distribution across both splits. For the CNN and CAE models, all images were resized to 224 × 224 pixels and normalised between 0 and 1. Data augmentation techniques (random rotation, flipping, and zooming) were applied to the training data to enhance generalisation and reduce overfitting. The dataset was further divided during training using a 5-fold cross-validation strategy, which allowed each model to be evaluated on unseen data across multiple training iterations.
Model configuration and hyperparameter tuning
Convolutional neural network (CNN)
The CNN architecture employed consists of three convolutional layers with increasing filter sizes (32, 64, 128), followed by max-pooling layers and ReLU activation functions. A flattening layer connects to a dense layer (128 neurons) and a final softmax output layer for binary classification (urban wild vs. non-urban wild). Dropout layers (0.3) were used after dense layers to prevent overfitting.
The model was compiled using the Adam optimiser with a learning rate of 0.001, categorical cross-entropy as the loss function, and accuracy as the primary performance metric. The batch size was set to 32, and the training was run for 50 epochs with early stopping based on validation loss (patience = 5). Hyperparameters were tuned via a manual grid search, testing the following ranges:
-
Filter sizes: 32, 64, 128;
-
Kernel sizes: 3 × 3, 5 × 5;
-
Dense layer sizes: 64, 128;
-
Dropout rates: 0.2, 0.3, 0.5;
-
Learning rates: 0.0005, 0.001, 0.005.
The best performing configuration was selected based on the highest average validation F1-score.
Convolutional autoencoder (CAE)
The CAE model consists of a symmetric encoder–decoder structure. The encoder includes three convolutional layers with ReLU activations and max-pooling to compress the input image into a latent vector. The decoder mirrors this structure using upsampling and convolution layers to reconstruct the original image. The model was trained using mean squared error (MSE) as the loss function and optimised with the Adam optimiser.
Training was conducted over 100 epochs with early stopping (patience = 7) and a batch size of 32. Hyperparameters tuned include:
-
Latent space size: 32, 64, 128;
-
Filter depth: 32, 64;
-
Reconstruction error threshold: 90%, 95%, 98% percentile of training error.
The reconstruction error threshold was used to classify images as relevant (low error) or noise (high error).
DBSCAN clustering
DBSCAN was employed as an unsupervised clustering algorithm for noise filtering. Feature extraction was performed using a pre-trained CNN model (ResNet50), where each image was converted into a 2048-dimensional feature vector from the penultimate layer. PCA was used to reduce the dimensionality to 50 components for computational feasibility.
DBSCAN parameters epsilon (ε) and minPts were tuned empirically. A range of values was tested: ε ∈ 0.3, 0.5, 0.7, 1.0 and minPts ∈ 3, 5, 10. The optimal configuration was found to be ε = 0.5 and minPts = 5, which produced compact and well-separated clusters. Evaluation metrics included the silhouette score, the Davies-Bouldin index, and manual inspection of.
image clusters.
Data cleaning
In this research, data cleaning is essential for transforming the raw scraped data from social media platforms into a high-quality dataset suitable for human engagement analysis. Since this data is gathered using hashtags linked to urban wild spaces, the scraped dataset contains all images associated with the provided hashtags. It consists of irrelevant or noisy content unrelated to urban wild spaces, inconsistencies, and AI-generated imagery. With the rise of AI-generated images—particularly those depicting urban wild spaces—this research needs to identify and filter out these synthetic images to maintain data integrity. This rigorous cleaning process ensures that the dataset exclusively includes human-captured images of urban wild spaces, offering a more genuine and accurate depiction of public engagement, perceptions, and interactions with these environments.
Experimental procedure
The experimental process involves three distinct machine learning models, each selected for its specific structural characteristics and methodological approach tailored to the task of filtering and analysing social media imagery related to urban wild spaces.
Experimental procedure for DBSCAN
The experimental procedure for using DBSCAN (Density-Based Spatial Clustering of Applications with Noise) in this research is focused on identifying patterns in user-generated content related to urban wild spaces and filtering out irrelevant or noisy data from the scraped datasets. DBSCAN is an unsupervised machine learning algorithm well-suited for identifying clusters within data and distinguishing noise, especially in datasets with irregularly shaped clusters, such as social media images tagged with diverse hashtags. Firstly, to effectively train and tune the DBSCAN model, a curated training dataset is prepared with images of urban wild spaces captured and labelled by expert researchers in the field, as mentioned before. Each image in this training set is associated with labels that provide a meaningful context, helping the algorithm understand relevant features indicative of authentic urban wild spaces. Though DBSCAN is unsupervised, this labelled data is used for initial exploratory data analysis, feature extraction, and validation purposes. It helps to understand the essential characteristics and clusters within this domain, informing parameter selection for DBSCAN.
Secondly, feature extraction and dimensionality reduction techniques are employed to translate the visual content of images into high-dimensional feature vectors. These vectors represent the essential characteristics of the images, such as texture, colour patterns, and structural elements typical of urban wild spaces. Given the high dimensionality of these feature vectors, dimensionality reduction techniques like Principal Component Analysis (PCA) or t-SNE (t-Distributed Stochastic Neighbour Embedding) are applied to reduce the data to a lower-dimensional space, making it more manageable for DBSCAN to process effectively.
The third phase of this research requires parameter selection and DBSCAN Model Training. DBSCAN requires two key parameters: epsilon (ε), which defines the radius of the neighbourhood around each point, and the minimum number of points (minPts) required to form a dense region or cluster. These parameters are tuned based on the characteristics of the training dataset. By examining the distribution of feature distances within the training data, we empirically select optimal values for (ε) and minPts that allow DBSCAN to form clusters around authentic urban wild space images while treating irrelevant or dissimilar images as noise.
The following Fig. 3 illustrates the DBSCAN (Density-Based Spatial Clustering of Applications with Noise) workflow as applied in this study to filter and cluster social media images related to urban wild spaces. The process begins with raw input images, which are transformed into structured image features through a feature extraction step. These features, representing high-level visual characteristics, are then fed into the DBSCAN algorithm, which uses two key parameters—epsilon (ε) and minPts—to identify dense regions of similar images. The output consists of well-defined clusters representing authentic urban wild space content and scattered noise points that are filtered out. This process enhances dataset quality by retaining only relevant, human-captured images for further engagement and sentiment analysis.

Visual representation of the DBSCAN clustering process applied to social media image analysis in urban wild space research46.
Since DBSCAN is unsupervised, it does not “learn” from the training data in the traditional sense but rather uses it to identify clusters and recognise outliers within the feature space. During the parameter tuning phase, the algorithm is iteratively applied to the training dataset, and the clustering results are analysed to ensure that relevant images form coherent clusters while irrelevant images are flagged as noise. This validation process helps confirm that the chosen parameters will generalise well when applied to the larger, unfiltered dataset scraped from social media.
Fourthly, after tuning, the DBSCAN model is applied to the scraped social media dataset, which contains images and metadata related to urban wild spaces collected through hashtag-based scraping. The experiment was run with multiple epochs to ensure better outcomes. Each image in this dataset is first processed through the density-based model to generate feature vectors, just like in the training phase. These vectors are then subjected to dimensionality reduction to ensure computational efficiency and facilitate clustering in a lower-dimensional space.
DBSCAN is used to analyse these feature vectors and form clusters based on similarity within the dataset. Images that fit within the established clusters (based on the density of points defined by ε and minPts) are retained as they likely represent authentic urban wild spaces. In contrast, images that do not belong to any cluster are labelled as noise and removed from the dataset. This clustering approach helps filter out content that does not match the patterns associated with urban wild spaces, such as irrelevant images, advertisements, or AI-generated images, which often have distinct feature profiles that prevent them from clustering with genuine images.
The expected results from the DBSCAN experimental procedure aim to demonstrate a high level of precision, recall, F-measure, and accuracy in filtering out noise from the social media dataset related to urban wild spaces. Precision is anticipated to be high, indicating that most images classified as relevant by DBSCAN are indeed authentic representations of urban wild spaces, minimising false positives. Recall is also expected to be strong, capturing a significant portion of relevant images without discarding them as noise, thereby reducing false negatives. A high F-measure would confirm a balanced performance between precision and recall, showcasing the model’s capability to maintain both relevance and completeness in the dataset. Additionally, the overall accuracy of the model reflects its effectiveness in distinguishing between genuine and irrelevant images, contributing to a high-quality, refined dataset. These metrics validate DBSCAN’s success in clustering authentic data while efficiently filtering out unrelated or AI-generated images, thereby supporting a more reliable analysis of public engagement with urban wild spaces.
Experimental procedure for CNN
The experimental procedure for using a Convolutional Neural Network (CNN) in this research consists of two main stages: training and testing. This process is designed to enable the CNN model to accurately identify and classify images relevant to urban wild spaces and to filter out noise or irrelevant data from the scraped social media dataset. Firstly, the training dataset consists of images specifically curated and labelled by expert researchers in the field of urban wild spaces. Each image is associated with a label that categorises it as relevant or irrelevant to urban wild spaces, with further subclassifications based on different types of natural environments (e.g., #CityWildlifePhotography, #greenspaces, #urbanwildspace). This labelling process ensures that the training data is high-quality, representing genuine examples of urban wild spaces, which provides a strong foundation for model learning.
Secondly, the CNN Model is trained using the training dataset. A typical CNN architecture consists of multiple layers: convolutional layers, pooling layers, and fully connected layers. During training, each convolutional layer applies filters to detect spatial hierarchies of features, starting from basic edges and shapes in the early layers to more complex patterns associated with urban wild spaces in the deeper layers. The pooling layers reduce the spatial dimensions of the feature maps, retaining the most prominent features while reducing computation load and preventing overfitting. The fully connected layers then take these extracted features to make predictions about the content of each image. The following Fig. 4 shows the Schematic of the Convolutional Neural Network (CNN).
The CNN model uses a supervised learning approach, where the labelled images are fed through the network in multiple training epochs. During each epoch, the model calculates a loss function that measures the difference between its predictions and the actual labels. Backpropagation is then applied, adjusting the weights of the CNN’s filters and neurons to minimise this loss. This process is repeated over many epochs, allowing the CNN to refine its understanding of what defines an urban wild space image. After training, the CNN is able to recognise these images with high accuracy, distinguishing between relevant and irrelevant content.
The third phase of this experiment is the testing and validation of the CNN model. After training, the CNN model is validated using a separate subset of the dataset (validation dataset) to assess its performance and fine-tune any parameters. Metrics such as accuracy, precision, recall, and F1-score are calculated to evaluate the model’s ability to classify urban wild space images while rejecting irrelevant images correctly. This step ensures that the model has learned effectively from the training data and is not overfitting to specific patterns or features. If the performance is satisfactory, the model is ready to be deployed on the larger scraped dataset.
Once trained and validated, the CNN model is applied to the raw scraped dataset obtained from social media platforms,

Architecture of a convolutional neural network (CNN) for image classification47.
which contains a variety of images associated with hashtags related to urban wild spaces. Given the nature of social media content, this dataset is expected to include noisy, irrelevant, or AI-generated images that do not genuinely represent urban wild spaces. The CNN model processes each image individually, analysing it to determine whether it fits the profile of an authentic urban wild space image based on the features it learned during training.
For each image, the CNN generates a probability score indicating how likely it is to belong to the urban wild spaces category. A predefined threshold is set: if the score exceeds this threshold, the image is classified as relevant; if not, it is flagged as noise or irrelevant. This automated filtering process significantly reduces and retains only those that align with the research focus.
After the CNN has processed the entire scraped dataset, the resulting data is reviewed to ensure accuracy and reliability. Any false positives (irrelevant images incorrectly classified as relevant) or false negatives (relevant images misclassified as irrelevant) can be manually reviewed and corrected if necessary. This step produces a final, cleaned dataset containing only authentic, human-captured images of urban wild spaces, free from noise or unrelated content.
Experimental procedure for convolutional autoencoder (CAE)
The experimental procedure for using a Convolutional Autoencoder (CAE) model to clean and analyse a scraped dataset from social media involves several stages: data preparation, model training, and data cleaning/testing. Convolutional Autoencoders are a type of neural network designed for unsupervised learning tasks, primarily used for dimensionality reduction and noise removal in image data. This model learns to compress input images into a lower-dimensional representation and then reconstructs them, helping to identify and filter out noisy or irrelevant content in our scraped dataset of urban wild spaces.
Firstly, the process begins with preparing a high-quality training dataset. This dataset comprises expertly, as mentioned. Each image in the training dataset is associated with specific labels and metadata to help the model distinguish between relevant and irrelevant features. This dataset is cleaned and free from noise, ensuring that it provides an accurate baseline for the CAE model.
Secondly, in the training phase, the CAE learns to encode and decode images from the training dataset. The Convolutional Autoencoder consists of two primary components: an encoder and a decoder. The encoder compresses input images into a low-dimensional latent space representation, capturing essential features while reducing noise and irrelevant details. The decoder then reconstructs the image from this compressed representation, aiming to replicate the original image as closely as possible. By minimising the difference between the original input and the reconstructed output, the model learns to focus on relevant features inherent in images of urban wild spaces, discarding less important information. The following Fig. 5 shows the basic architecture for an autoencoder.

General architecture of a convolutional autoencoder (CAE) for image reconstruction and noise filtering48.
In the Fig. 5 Functions f (x) and g(h).
-
f (x): This represents the encoding function, which transforms the input image x into the latent code h. The function f (x) includes all the operations (convolutions and max-pooling) applied in the encoder to reduce the input to its compressed form.
-
g(h): This is the decoding function, which takes the latent representation h and reconstructs it back into an output image r. The function g(h) includes all the operations (convolutions and upsampling) in the decoder, which aim to reconstruct the original image from the compressed code as accurately as possible.
The loss function Convolutional Autoencoder (CAE) used in this process is typically Mean Squared Error (MSE), which quantifies the reconstruction error by calculating the difference between the input image and the output image. As the CAE iterates over the training dataset, it optimises its weights to minimise this reconstruction error, becoming proficient at encoding and reconstructing images of urban wild spaces. The model is trained over multiple epochs, with the training data passed through the network several times to ensure it captures all distinctive features of the domain. Once the model achieves a low reconstruction error, it is ready for testing on the scraped dataset from social media.
In the third phase of this experiment, after training, the Convolutional Autoencoder is tested on the raw scraped dataset, which includes images gathered from social media platforms. This dataset is likely to contain noisy, irrelevant, or AI-generated images due to the nature of user-generated content on social media. The goal is to use the CAE to filter out these irrelevant images, leaving only authentic and relevant content related to urban wild spaces.
When each image from the scraped dataset is passed through the trained CAE model, the model attempts to encode and reconstruct it. Suppose the image closely resembles the types of images in the training dataset (i.e., genuine urban wild spaces). In that case, the model will be able to reconstruct it accurately with a low reconstruction error. However, suppose the image contains irrelevant or unfamiliar content (such as unrelated scenes, heavily modified images, or AI-generated content). In that case, the model will produce a higher reconstruction error because it cannot encode these images effectively based on its learned representation of urban wild spaces.
A threshold for reconstruction error is set based on the performance of the model during training. Images with a reconstruction error below this threshold are classified as relevant and authentic, whereas those with a reconstruction error above the threshold are flagged as noise or irrelevant. This threshold-based filtering allows the CAE to automatically clean the dataset by identifying and removing images that do not match the characteristics of true urban wild spaces.
The cleaned dataset is then free of irrelevant and noisy images and is ready for further analysis. This dataset contains only images that are likely to represent real urban wild spaces, ensuring the authenticity and relevance of data for studying public engagement. The effectiveness of the CAE model can be evaluated by manually checking a subset of flagged images and comparing them with images that were retained. This helps refine the threshold for reconstruction error and adjust the model’s sensitivity as needed.
link







