



This methodology describes the complete pipeline for training a YOLOv11, Faster region-based convolutional neural network (Faster R-CNN), and Vision Transformer (ViT) to detect dental fillings, root canal material, endodontic posts, and dental prostheses (crowns and bridges) in panoramic radiographs. The workflow (Fig. 1) involves the preparation of the data set, the selection of the models, the training, the evaluation, and the deployment. This study was reported using the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) 2024.


Workflow diagram of the methodology showing the Data annotation, preprocessing and Model deployment
Dataset
Multiple sources provide more than 2,235 radiographic images that originated from Pakistan [13], Thailand, and the USA [14]. Summary of the dental panoramic X-ray dataset, including image count, source distribution, and dataset splits for training, validation, and testing, is presented in Table 1. The collection contains radiographic images that showcase numerous dental conditions due to differences in prosthetic dentistry structure types and oral health patterns among populations. Table 2 presents the distribution of annotated instances of the six classes in the dataset with the division into training and validation sets. The highest number of instances is the Dental Fillings class and then the Crown and then the root canal treated tooth. The dataset contains 11,462 instances altogether. Radiographs, from patients who have undergone various treatment histories ranging from untreated decay to past procedures and complex prosthetic work, include dental radiographs (panoramic) with labels for six dental treatments: fillings, implants, crowns and bridges (dental prosthesis), root canal materials, endodontic posts used in root canals, and dental implants. The provided code uses this dataset to train various models for detecting these treatments, experimenting with different methods and settings. For more details, please see the READ ME.txt file [15]. The utilization of dental radiographs from various international regions allows the model to adapt effectively to different patient and clinical situations. The dataset represents a wide range of imaging techniques and exposure conditions, as well as different radiographic qualities, to improve the detection model’s performance reliability. Different imaging conditions within the dataset bring specific challenges that affect such aspects as contrast quality, anatomical visibility, and artifact detection because the dataset remains faithful to actual clinical scenarios. The study excludes implant-supported bridges, long-span dental bridges, orthodontic mini-implants, cases of dental trauma, deciduous and mixed dentition, as well as panoramic (OP) with excessive noise or artifacts. Included in the study are dental prostheses, dental restorations, endodontic posts, root canal-treated teeth, and dental implants. This study was approved by the Human Research Ethics Committee of the faculty of Dentistry, Chulalongkorn University (HREC-DCU 2024-093).
Data labelling
Annotation of the data set led to the proper training of YOLOv11, ViT, and Faster R-CNN, which resulted in the accurate interpretation and classification of dental radiographic images. Roboflow and CVAT are two different platforms that were used for the data annotation process. The annotation procedures required bounding boxes and polygons to surround target objects while preparing datasets that suited YOLOv11, Faster R-CNN, and ViT. Figure 2 displays the six annotated classes: crown, dental fillings, endodontic post, root canal-treated tooth, bridge, and implant. The detection performance required detailed labelling because dental structures have different levels of complexity and radiographic images show variable image quality.


Data annotation of different classes by using Roboflow
YOLOv11 and ViT demanded annotation through.txt files containing object class IDs together with normalized bounding box values (Xcenter, Ycenter, width, and height). The optimized detection performance comes from this processing format, which maintains efficient speed during real-time operations. The annotations for Faster R-CNN were saved with bounding-box coordinates listed in absolute pixel values through Pascal VOC (.xml) and COCO (.json) formats. Detectable dental prostheses and fillings can benefit from these formats as they enable the model to identify spatial features between different dental prostheses and filling objects.
Different OPGs displayed multiple dental labelling as defined earlier, so the annotation process needed to handle more than one label. Multiple structures with overlapping boundaries received specific labels for distinction purposes. The model received specific attention for instances where dental implants near crowns because the model needed to correctly recognize these dental structures. Manual review procedures were used to solve annotation problems caused by differences in radiographic levels and image noise between images acquired from Pakistan, Thailand, and Tufts University [13,14,15]. To ensure high-quality ground truth, annotations were carried out by three dental specialists: a prosthodontist, an endodontist and a restorative dentistry consultant, each with more than 10 years of clinical experience. Categories were defined based on established restorative dentistry guidelines. Ambiguous cases, such as differentiating resin-based versus metallic posts or post–crown combinations following root canal therapy were resolved through consensus discussion. The annotation protocol required clear delineation of restoration boundaries using bounding boxes or polygons, depending on structural complexity. To confirm reliability, 15% of the dataset was randomly selected for cross-review, yielding a high inter-rater agreement (Cohen’s κ = 0.89), thereby demonstrating consistency and accuracy of the labeling process. After labelling data scientist helped in model selection and automated the conversions of the formats of the dataset.
Data preprocessing
To ensure optimal training performance for YOLOv11, Faster R-CNN, and ViT, several preparatory stages were used to standardize the dataset, increase image quality, and improve model generalization. As there were a lot of variations in the data because of different demographics, preprocessing was necessary to handle differences in resolution, contrast, and imaging quality.
a) image resizing
Diverse image qualities existed in the dataset because radiographic images originated from multiple sources in Pakistan, Thailand, and Tufts University, creating inconsistencies in resolution, pixel density, and aspect ratios. Receiving inconsistent input sizes from these datasets became a problem for deep learning models because they produced substandard feature extraction while requiring more computing power. The input requirements of YOLOv11 and Faster R-CNN guided the homogenization process for all images by resizing them to specified dimensions without distorting their anatomical integrity.
The YOLOv11 input images and Vision Transformer received 640 × 640 pixel dimensions, which serve as the conventional standard measure for real-time object detection applications. The chosen resizing process delivered optimal processing efficiency without harming either performance speed or feature maintenance capabilities. A fixed input size proved essential to YOLO since grid-based detection requires this to avoid mapping inconsistencies.
Faster R-CNN operates on images with a 1024 × 1024 pixel size because the model depends on precise anatomical details for effective object detection. Since Faster R-CNN operates on proposals instead of grids, it requires higher resolution images to function optimally. Better localization of small dental elements, including web-based fillings and endodontic posts, becomes possible through enhanced resolution.
Maintaining correct aspect ratios between image dimensions formed a main barrier in the process of resizing dental prostheses without distortion. When images were resized directly, they deformed their anatomical structures, thus impairing learning capabilities for the model. The problem required resolution through letterboxing (zero-padding) applications. This technique ensured the preservation of original proportions through black padding, which adjusted the shorter dimension to create a square input without any dimension deformation. Techniques that resize images take into consideration the differences found in X-ray imaging quality. The enhancement of radiograph visibility through the combination of resizing techniques and contrast normalization occurred because various imaging machines and exposure protocols created radiographs with different pixel intensity levels. The resizing process protected the necessary structural information that allowed the reliable detection of dental prostheses among various groups of patients.
b) data augmentation
The radiographic image dataset included multiple normative variations in imaging methodology, as well as structural dental data and prosthetic formats between images. Some classes, especially dental fillings and endodontic posts, appeared infrequently, which could create model bias. The results required corrections because of data disturbances, so data augmentation techniques corrected these problems to support better model generalization functions. Increasing methods artificially increased the diversity of images by applying variances in image dimensions without modifying anatomical structures.
HSV (Hue Saturation Value) augmentation procedures were utilized for imaging variation simulation based on different X-ray machine types and exposure settings. The Value channel adjustment method in this technique simulated both excessive and insufficient exposure while enhancing the lighting variations tolerance of the model. Adjusting Saturation parameters enabled steady image sharpness by using both saturation increase and decrease methods for grayscale tones. The original black and white picture format was modified through small hue changes to represent pixel brightness fluctuation, which generated realistic image deviations. Different artificial modifications of the model collectively improved its ability to learn generalizable patterns, which led to reliable performance across diverse radiographic imaging scenarios.
Augmentation through scaling has been employed for random width and height transformations up to ± 10% that produced different prosthesis dimensions. The X-ray acquisition angle variations up to 15 degrees were considered through rotation transformation intervals. The introduction of shearing and translation functions established minor image movement that replicated various imaging point perspectives. The model utilized horizontal flipping methods only on prostheses presenting symmetrical elements to enhance its performance in recognizing mirrored patterns. The use of these augmentations resulted in a substantial enhancement of model robustness, which enabled it to accurately detect dental prostheses within various imaging conditions.
$$\:{Flip}_{Horizontal}\left(I\right)={I}_{flip}\:\left[x,y\right]=I[w-x,y]$$
$$\:{Flip}_{Vertical\:}\left(I\right)={I}_{flip}\:\left[x,y\right]=I[x,h-y]$$
Whereas “I” represents the image, w is its width, h represents height, and x and y are the horizontal and vertical indices of a pixel, respectively.
The model received Gaussian noise through controlled mechanisms as a method to make it more resilient against X-ray quality variations. The model-training process incorporated different levels of simulated image graininess to acquire the ability to detect prostheses across high-quality and poor-quality X-ray images. Some classes, such as Endodontic posts, were less represented in the dental data. Choosing augmentation methods enabled the development of a more extensive number of examples for underrepresented classes compared to the more common ones. More intensive manipulation of the rarely seen classes took place during augmentation to preserve their natural anatomical forms. A better clinical representation of the dataset was achieved through the application of techniques, which included contrast modulation with geometric distortion and noise layering and selective augmentation of minority groups. The detection system operated effectively with dental prostheses under any medical imaging or patient demographic conditions.
Object model deployment
After training and evaluation, the optimized models were deployed for real-time inference and clinical integration. All YOLOv11, Vision Transformer, and Faster R-CNN were deployed using efficient strategies tailored to their respective architectures, ensuring accurate and efficient detection of dental prostheses, dental fillings, root canal treatments, and endodontic posts in radiographic images.
YOLOv11
YOLOv11 is the latest addition to the YOLO family, designed to further improve accuracy, efficiency, and real-time performance. Built on the foundation of its predecessors, YOLOv11 introduces novel enhancements in feature extraction, multi-scale processing, and prediction refinement, making it highly effective for object detection in complex environments such as dental prosthesis detection in radiographic images.
Backbone network
The backbone network is responsible for extracting spatial and semantic information from input images. YOLOv11 uses an advanced convolutional architecture in as shown in Fig. 3. The key features of the backbone include:

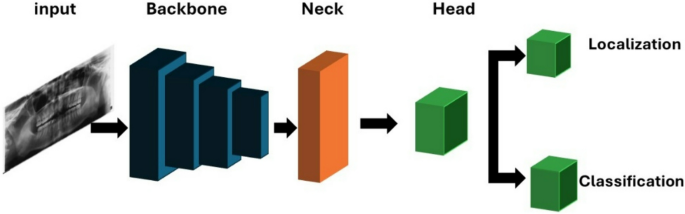
YOLO Framework with backbone, neck, and dual-output head for localization and classification tasks
-
Lightweight Convolutional Layers: Uses depth-wise separable convolutions to reduce computational load while preserving high-quality feature extraction.
-
Efficient downsampling: Implements strided convolutions and pooling layers to progressively reduce spatial dimensions while retaining significant object information.
-
Residual Connections: Inspired by ResNet, these connections improve gradient flow, reducing the likelihood of vanishing gradients and enhancing model stability.
Feature pyramid network (FPN)
To facilitate accurate detection across different object sizes, YOLOv11 integrates a Feature Pyramid Network (FPN). This component enhances the model’s ability to detect small and overlapping objects by combining features at multiple resolutions. The key improvements in FPN include:
-
Multi-Scale Feature Fusion: Merges fine-grained small-scale details with global semantic information, improving detection accuracy.
-
Bidirectional Feature Flow: Allows two-way information exchange between different layers, refining feature representation across multiple resolutions.
Detection head
The detection head in YOLOv11 has been redesigned to improve both localization and classification accuracy. The primary enhancements include:
-
Anchor-Free Object Detection: Unlike previous YOLO models, YOLOv11 eliminates the use of anchor boxes, reducing computational load and improving adaptability to various object sizes.
-
Adaptive Receptive Fields: Dynamically adjusts receptive field size based on object position, improving the detection of overlapping dental prostheses.
-
Optimized Prediction Heads: Uses multiple output layers to predict class labels, confidence scores, and precise bounding box coordinates in a single forward pass.
Efficiency and computational optimization
To achieve real-time performance without compromising accuracy, YOLOv11 integrates multiple efficiency optimizations:
-
Model Quantization and Pruning: Reduces model size and computational requirements, enabling deployment on low-power edge devices.
-
Optimized Activation Layers: Uses SiLU (Sigmoid Linear Unit) activation to accelerate convergence and stabilize gradient updates.
-
Parallelized Computation: Implements multi-threaded GPU acceleration, reducing inference latency and improving detection speed.
Faster R-CNN
Faster R-CNN is a real-time object detection model with high accuracy, incorporating a Region Proposal Network (RPN) for efficient region selection. Unlike traditional two-stage detectors that rely on computationally expensive algorithms such as Selective Search, Faster R-CNN dynamically generates region proposals, significantly improving speed and accuracy. The framework (Fig. 4) consists of several key components, including the backbone network for feature extraction, the RPN for proposal estimation, RoI pooling for fixed-size feature generation, and the detection head for classification and localization.


Faster RCNN Architecture showing the complete pipeline from input image through convolutional layers, feature map extraction, region proposal network (RPN) with object classification
Backbone network
The backbone network is responsible for extracting meaningful feature representations from the input image. Faster R-CNN typically utilizes deep CNN architectures such as ResNet or VGG to enhance feature learning. The backbone consists of:
-
Hierarchical Convolutions: Captures both low-level edges and high-level object features.
-
Feature Maps: Provides representations for downstream processing in the RPN.
-
Pretrained Weights: Leverages ImageNet-trained models to improve detection accuracy.
Region proposal network (RPN)
The RPN generates object proposals directly from feature maps, eliminating the need for external methods. It consists of:
-
Sliding Window Convolution: Runs a lightweight network over feature maps.
-
Anchor Boxes: Uses predefined anchor boxes at multiple scales to detect objects of varying sizes.
-
Proposal Refinement: Classifies each region as foreground (object) or background, refining bounding boxes for better accuracy.
Region of interest (RoI) pooling
RoI pooling extracts a fixed-size feature representation from region proposals. This step ensures that all proposed regions have a uniform shape for further processing. It includes:
Detection head
The detection head classifies objects and refines bounding box coordinates for accurate localization. It consists of:
-
Softmax Classifier: Assigns a class label to each detected object.
-
Bounding Box Regression: Adjusts bounding box coordinates to improve localization precision.
-
Non-Maximum Suppression (NMS): Removes redundant or low-confidence predictions, ensuring that only the most reliable detections remain.
Vision transformer
Vision Transformer (ViT) is a groundbreaking deep learning model that uses transformer architecture, which was originally designed for Natural Language Processing (NLP), in computer vision features. Unlike transport-neutral networks (CNNS), which rely on an interdisciplinary filter to capture local spatial properties, ViT uses a collaborative mechanism to model global relationships in an image. This global meditation is especially powerful for complex image classification features, such as dental diagnosis, where locally distant properties can be important. In our study, we use a ViT-based model to classify dental temperatures into six categories: tooth crown, dental filling, bridge, dentist mail, root filling, and dental implant. The Vision Transformer (ViT) provides a visual diagram (Fig. 5) which represents an image classification process through patch division and linear projection to sequence with position embeddings, followed by a transformer encoder and an MLP head [16].


The Vision Transformer (ViT) provides a visual diagram which represents an image classification process through patch division and linear projection to sequence with position embeddings followed by a transformer encoder and an MLP head
Image processing
The ViT images first process images by dividing them into fixed-size non-subject tags, usually 16 × 16 pixels. Each patch is flattened and led through a linear layer to create a high-dimensional built-in. Since transformers do not originally understand the spatial structure, patch order and position coding are added to build in to preserve the spatial ratio.
Transformer encoder and classification
These rich built-ins are then passed through a series of transformer coder layers, each of which includes multi-headed self-rights and forward networks (FFN). A learning classification token (CLS symbol) is presented to the patch sequence, and it learns how to gather information in all patches. After the final coder block, the CLS symbols are pulled out and passed through a multilayer Perceptron (MLP) head, which sends out class options for six tooth categories.
Advantages and suitability
It allows the architectural model to capture both local and global patterns, especially suitable for tooth image analysis. Although ViT requires sufficient data and calculation resources, its ability to model long-distance dependency makes it a powerful alternative to traditional CNNs. Pretrained ViTs fine-tuned on datasets can significantly increase the performance of the dental image scenarios on the domain-specific dataset.
Evaluation metrics
YOLOv11, Faster R-CNN, and ViT have been utilized for the detection and classification of dental restorations and prosthesis in panoramic radiographs. These models vary a lot in their architecture and evaluation matrices. YOLOv11, Faster R-CNN are object detection models, while ViT, being based on transformers, is an image classification model. Consequently, different metrics of evaluation have been used in the related models. Object detection models usually evaluate the quality of predicted bounding boxes for the consideration of their performance (e.g., mean Average Precision (mAP) and Average Precision (AP) at different Intersection over Union (IoU) thresholds). IoU calculates the overlaps between the predicted bounding boxes and the actual bounding boxes as the ratio of the intersection to the union. Some of the common IoU thresholds used in evaluating how close a detection is to the ground truth include 0.50 and 0.75, among others.
On the other hand, the classification models such as ViT focus on the measures of accuracy, precision, recall, the F1-score, and the loss. Leading to these differences in the criteria of evaluation, and non-uniform presentation of metrics for all models, Precision has been chosen as the common criterion to use for comparative analysis. Precision is always indicative of the model’s capability of finding true positives correctly, which is of particular importance in the case of medical imaging applications, whereby false positives may have clinical implications.
link